Regarding our new paper: Differentially Private Gaussian Processes.
In layman terms Gaussian Processes (GPs) are, usually, used to describe a dataset, to allow predictions to be made. E.g. given previous patient data, what is the best treatment a new patient should receive? It’s a nice framework as it incorporates assumptions clearly, and, because of its probabilistic underpinnings gives estimates of the confidence for a particular estimate.
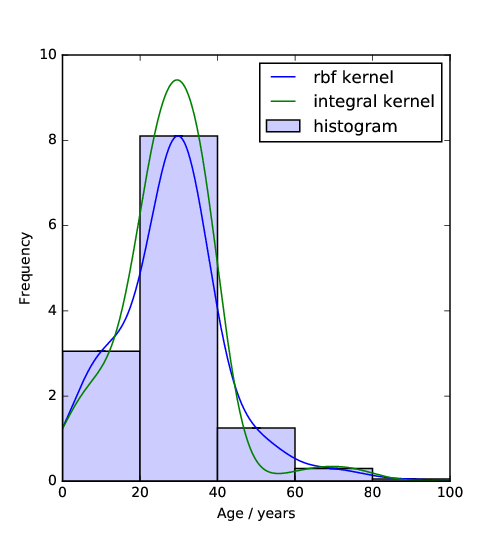
Comparison of new ‘integral’ kernel with a normal RBF kernel. Note the underestimate the RBF kernel suffers between 20 and 40 years.
Differential Privacy is a method that’s recently started to go main-stream. I’ve written a brief introduction presentation here. The general idea is to add noise to any query result to mask the value of an individual row in a database, but still allow inference to be done on the whole database.
My research areas cover both Gaussian Processes and Differential Privacy, so it seemed to make sense to see if I could apply one to the other. In our latest paper we look at two ways to do this:
- Bin the data and add differential privacy noise to the bin totals. Then use a GP to do the inference.
- Use the raw non-private data to train a GP, then perturb the GP with structured noise to achieve DP.
For the former I developed a new kernel (a way of describing how data is correlated or structured) for binned or ‘histogram’ data. See this ipython notebook for examples. This hopefully is useful for many applications (outside the DP field). For example any inference using binned datasets. At the moment I’ve only applied it to the RBF kernel.
For the latter I used the results of [1] to determine the noise required to be added to the mean function of my GP. I found that we could considerably reduce the noise scale by using inducing (pseudo) inputs.
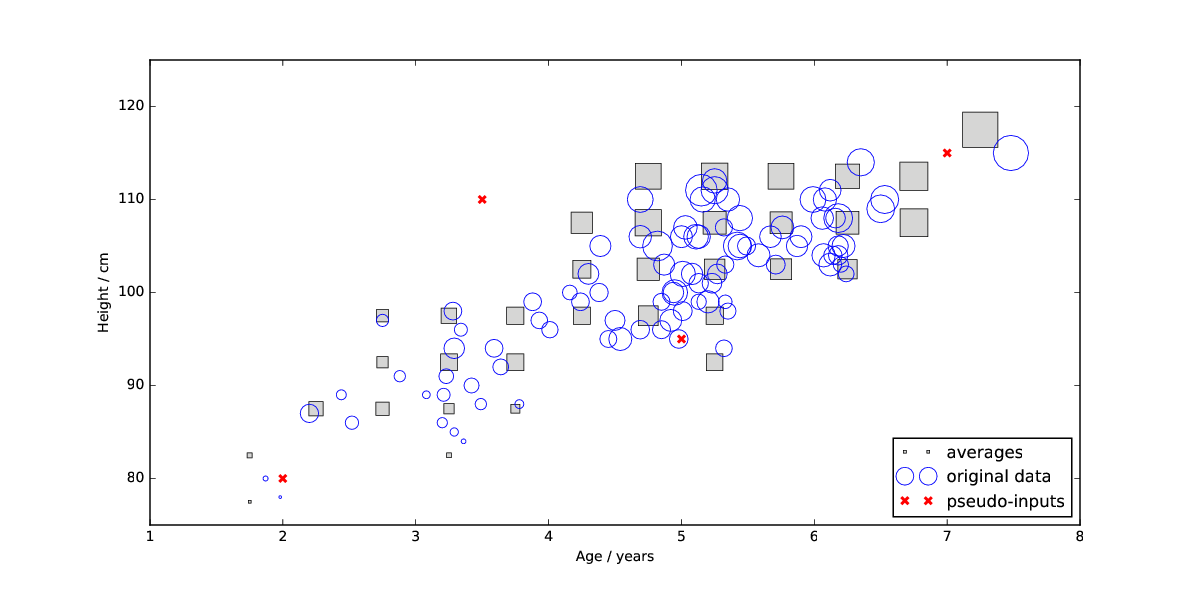
Malawi child dataset. Raw data and 2d histogram.
Both methods can be further improved, but it’s still early days for Differential Privacy. We need to look at how to apply DP to as many methods as possible, and start to incorporate it into more domains. I’ll be looking at how to apply it to the MND database. Finally, we need an easy “introduction to DP for practitioners”. Although I don’t know if the field is sufficiently mature for this yet.
[1] Hall, R., Rinaldo, A., & Wasserman, L. (2013). Differential privacy for functions and functional data. The Journal of Machine Learning Research, 14 (1), 703–727.